
Table of Contents
- Overview
- Event Manager Design
- Event Manager Model
- Example
- Main pieces of EM scheduler
- Event Manager Primary Function
- Understanding EM queues
- Event Manager JMS Queues and Topics in WAS
- Understanding general parameters of EM
- Event Manager Monitor
- Troubleshooting issues related to EM
- New in BPM 8.5.5 - EM thread pool
- Other EM related tips
Overview
In this article I would like to focus on different parts that IBM BPM (Standard) Event Manager consists of. How they stick together and why EM is quick and efficient. This article is primarily based on the knowledge that I gathered during the Lombardi Bootcamp back in 2007 (you will be surprised but EM didn't change much since then) as well as 7 years in L2 Support of Lombardi and later IBM BPM Products.
Event Manager Design
In the Event Manager (EM) design the database the master of everything.
The important Event Manager related table in BPMDB are:
lsw_em_instance - A row for each EM scheduler.lsw_em_task - A row for each non-completed task, includes a reference to lsw_em_instance to indicate which scheduler owns each task.lsw_em_task_keyword - One-to-many table mapping a task to its associated keywordslsw_em_sync_queue - A row for each sync queue, includes a reference to lsw_em_instance to indicate which scheduler owns each sync queue.lsw_uca_blackout - A row for each blackout period, including the next transitions into and out of blackout
The database knows what schedulers exist, what sync queues exist, what tasks exist, what states the tasks are in, etc. So, basically Event Manager uses the database’s transactional guarantees as much as possible to ensure a consistent view across all machines in a cluster. In addition, Event Manager uses the database’s system clock as the master, to avoid problems with time-syncing among machines in a cluster.
Event Manager model
A Task is a single thing to be scheduled
A Task includes an arbitrary set of keywords
Arguments passed to a task’s executor
Note that a Task in this case can be any of the task that is executed by EM. EM "Scheduler" is responsible for execution of UCAs, but is also used for processing BPD notifications (special kind of tasks that are used to move the token from one activity to another in the BPD flow), executing BPD system lane activities, and executing BPD timer events.
EM "Scheduler" doesn't include the pieces of the EM that listen for JMS or HTTP messages and fire events, nor the pieces of the BPD engine that sends BPD notifications.
A task includes an arbitrary set of keywords which can be used in any combination to cancel or reschedule tasks. A UCA execution task, for example, has several different cancellation modes. Imagine that a blackout period is in effect, and a UCA is triggered by several instances of its event, and/or several executions of an InvokeUCA component. This will create several different tasks, scheduled for immediate execution and so, the keywords are used to control that behavior on whether we need to reschedule or cancel the execution.
If we change the UCA’s schedule, we should cancel the scheduled-execution task, and create a new task for the new scheduled time. If we delete the UCA entirely, we’d want all tasks related to that UCA (scheduled, event, invokeUCA) to go away. This is all accomplished by giving each task a set of keywords, and cancelling tasks based on keywords (see example below).
Another important piece is the arguments passed to a task’s executor. This arguments string (of unlimited length) allows passing arbitrary data from the original scheduler of the task to the task’s executor – in the case of UCAs, we include the UCA’s ID and any parameters specified by the caller. When scheduling a task, we can pass a Blackout Behavior, which indicates how it should be handled if this task’s scheduled execution comes during a blackout period.
Example
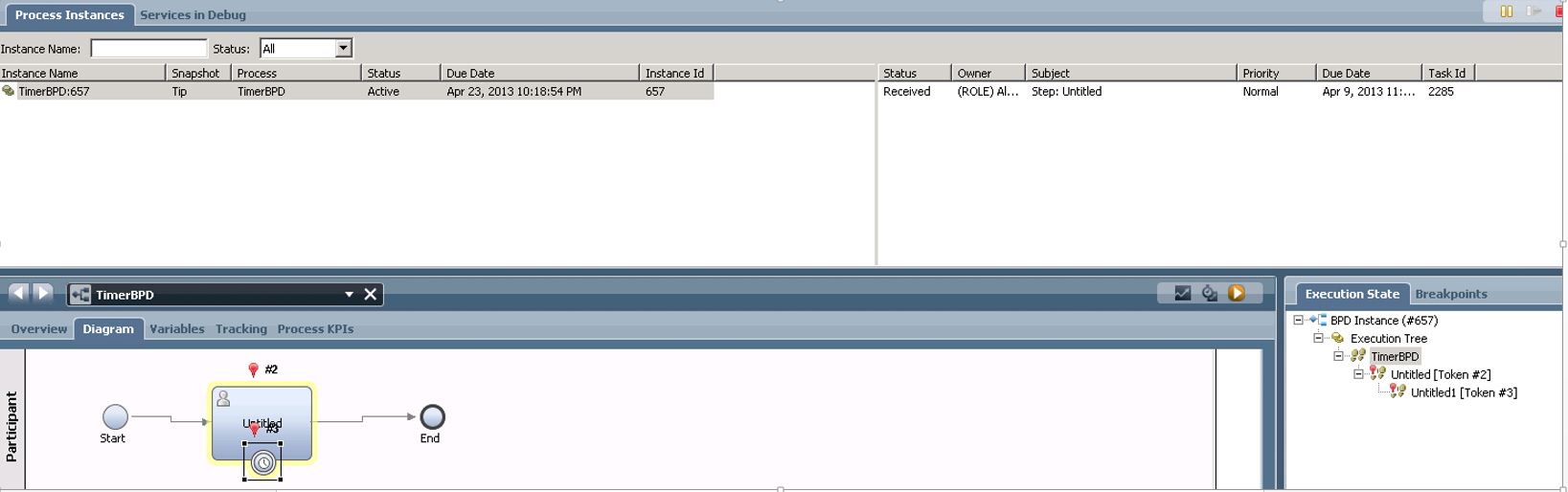

In above example we can see that on first screenshot there is a BPD instance view in Process Inspector. We can see that the instance id is 657 and the task id for a single task where the token resides is 2285. Note that there is also a token on an intermediate timer event!
Now let's take a look at the contents of LSW_EM_TASK table (second screenshot) - we can see that this table has its own task_id field and it does NOT correspond to a human task. Instead this is an Event Manager Task that corresponds to BPD timer event. If there would be no timer event attached to the activity then there would have been no records in LSW_EM_TASK table.
Few more words on LSW_EM_TASK table and specifically, column called "TASK_STATUS". The task status in this specific table is not the same like in LSW_TASK because these are EM tasks and not regular BPM tasks. So, TASK_STATUS in this case has values from 1 to 4 -
1 - SCHEDULED
2 - ACQUIRED
3 - EXECUTING
4 - BLACKED_OUT
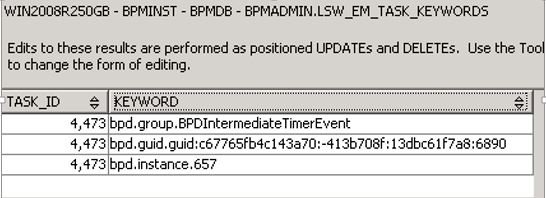
Finally, on the last screenshot we can see contents of LSW_EM_TASK_KEYWORDS that we discussed in "Event Manager model" section above. As you can see there are three rows for a single EM task in this table. First row represents what kind of task it is - BPDIntermediateTimerEvent. Second row gives us information about the guid of a BPD that this task is executed from and the third row shows the instance id # that corresponds to an instance of our example BPD. These keywords allow event manager to perform a proper execution of the timer event.
Main pieces of Event Manager scheduler
Heartbeat - periodically updates lsw_em_instance to signal to other schedulers that this scheduler instance is connected. The heartbeat continues even when a scheduler is paused, so that it would be possible to tell the difference between a paused scheduler and a disconnected one. All references to lsw_em_instance (from lsw_sync_queue and lsw_em_task) are only considered valid if the corresponding lsw_em_instance row has a non-expired heartbeat. The lsw_em_instance table has a heartbeat_expiration column; the Heartbeat periodically (every 15 seconds be default) updates this value to be current_time + 1 minute. The Heartbeat and any other scheduler pieces that look for non-expired scheduler instances compute and compare based on the database’s current time, never the Application server's.
TaskLoader - the TaskLoader periodically polls the database, looking for new sync queues to acquire and new tasks to acquire. The main part is that sync queues and tasks to be assigned to clustered schedulers in a well-balanced way but without additional complexity. So, each TaskLoader acquires one sync queue at a time, and a configured number of tasks at a time. If there are many tasks, TaskLoaders will take turns acquiring chunks of tasks – as long as their polling periods and chunk sizes are the same, the load will be balanced.
In order to be eligible for acquisition, a task must meet all of the following criteria:
• Scheduled to execute in the past or in the next loader_window milliseconds (based on the database’s system clock)
• Run on an async queue or on a sync queue that is owned by this scheduler
• Not in the “blacked out” state
• Not owned by any scheduler, or owned by a scheduler with an expired heartbeat
When TaskLoader loads tasks, it marks them to indicate that they have been acquired by this scheduler, and passes the tasks off to the Engine for execution. It also adjusts the tasks’ scheduled times by estimating what the current machine’s time will be when the database machine’s time matches each task’s scheduled time.
Engine - the Engine is responsible for the actual execution of tasks. When TaskLoader hands tasks to the Engine, the Engine schedules them by handing a wrapped task to a simple utility class that schedules in-memory task execution.
Once the tasks are loaded, the TaskLoader hands them off to the Engine. The Engine has an in-memory list of tasks by execution time.
At the task's execution time, the Engine hands the task off to its threadpool for execution. The engine's threadpool always has between <min-thread-pool-size> and <max-thread-pool-size> threads in it; if it has no spare threads, the task waits until another task completes. There is no facility for releasing the task to be picked up by a different scheduler, so the threadpool should always be big enough to accommodate the total concurrent capacity
I will not be going into the weeds of how the EJBWorkflowManager (service engine) bean works and so on and so forth. It's just important to understand that Engine is responsible for the actual execution of tasks.
Coordinator - when a Coordinator is instantiated, it creates a Heartbeat, TaskLoader, and Engine, and connects them to each other. It coordinates start/stop/pause/resume/shutdown operations, as well.
TaskManager - the TaskManager is a utility class used for scheduling new tasks, cancelling existing tasks, and rescheduling existing tasks. It is not used in the runtime operation of the scheduler, but is the way that other pieces of the BPM system interface with the scheduler.
Event Manager Primary Function
The Event Manager’s primary function is to guarantee scheduled execution of code. Note that the Event Manager is not executing the code, but scheduling it with the corresponding Process Center/Server.
Any work scheduled by a specific EM will be run on the local Process Center/Server. The EM scheduler is used anytime a UCA is invoked, but is also used for processing BPD notifications, executing BPD system lane activities, and executing BPD timer events.
In other words, we may say that the EM is the broker that drives BPD execution and UCA Execution. Each BPD token progression is a BPD task in the EM (BPD notification task that you can observe in EM Monitor in Process Admin console whenever token is progressed from one activity to another).
By default, every time IBM BPM asks the EM to do work (UCA, bpd notification to advance a token, etc), it forces the EM to reload its queues from the db and do work immediately.
Understanding EM queues
To better understand the Event Manager you must first understand EM queues
- There are two types of EM queues: Asynchronous (async) and Synchronous (sync). Async queues are executed as soon as possible with no guaranteed order. Sync queues are executed serially. If you have multiple tasks set to run on one sync queue they will execute one after the other in the order that they were put in to they sync queue. The EM treats sync and async queues differently.
- Sync Queue - each task in a sync queue must be executed in serial. To prevent problems in a cluster, an EM will claim ownership of one or more sync queues when it starts up. The ownership is stored in the LSW_UCA_SYNC_QUEUE where QUEUE_OWNER is linked to OWNER_ID in LSW_EM_INSTANCE. This is not a permanent assignment. The LSW_EM_INSTANCE table keeps track of status of all of the event managers. The status is checked every 15 seconds by default. If the owner of a sync queue is no longer available another EM will take ownership of that sync queue.
- Async Queue - Async tasks are picked up by each EM when there is room in their async queue for more tasks. Each process server has it’s own running EM. The EM is configured by each process server’s copy of 80EventManager.xml: There are various EM settings in that xml file and they are all specified in milliseconds.
Event Manager JMS Queues and Topics in WAS
eventqueue - this is the queue that can be used to post a message to the Event Manager. If you want to post a message from an external system to the Event Manager, you must use the special message structure as described in this infocenter article.
In turn if the message you sent to eventqueue has incorrect syntax or could not be processed it would end up in eventerrorqueue. You can view the contents of eventerrorqueue using the BPM Process Admin console -> Event Manager -> EM JMS Error Queue
Typically this approach to post a message to EM queue is used when you want your external messaging system to send a message to BPM. So, you would send BPM a message by sending a message to the jms eventqueue. This event would then kick of a UCA. The advantage of this approach is you don't have to run a UCA on a schedule to pick up messages from your external system, instead you get the message from your external system as soon as it has one to send to you. It also scales much better than if you would have BPM to keep pulling data from an external system queue.
EventMgrControltopic - this JMS topic is used for sending pause and resume commands. If you go to Process Admin Console -> Event Manager -> Monitor -> you will see that you can Pause/Resume each of the EM instance here and this topic is used to send those pause/resume commands.
Understanding general parameters of EM
The default settings for the scheduler should be fine for the vast majority of deployments. You should be careful when tuning any of the EM parameters and any changes should be backed up by extensive testing.
There is a technote that explains all of the parameters:
Understanding and Tuning the Event Manager
4.5.2 Tune the Event Manager in IBM Business Process Manager V8.0 Performance Tuning and Best Practices RedBook.
Event Manager Monitor
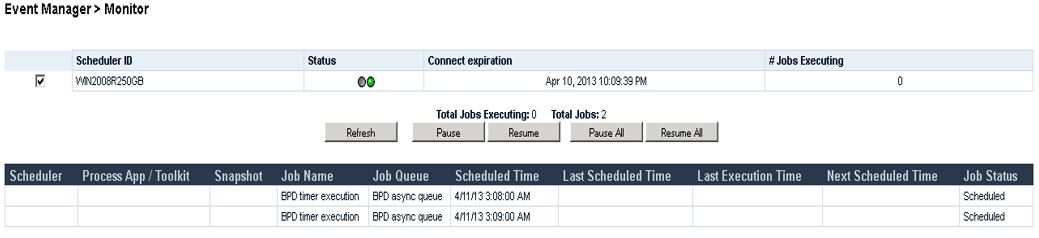
The Event Manager monitor in the Process Admin Console displays information about the Scheduler for the Event Managers on your Process Center server or Process Server server and about the various jobs being tracked by that Scheduler. Note that EM Monitor page shows all the connected and disconnected Event Managers in BPM clustered environment.
In Event Manager monitor you can see the status for each scheduled job. There are three states for any EM task: scheduled/acquired/executing. The Scheduler column will tell you which scheduler has picked up the job when it's ready to be executed.
Troubleshooting issues related to EM
Two main troubleshooting paths:
1) In 80EventManager.xml (best practices would be to perform an override in 100Custom.xml):<task-execution-listener>
com.lombardisoftware.server.scheduler.DbTaskExecutionListener
</task-execution-listener> - this is disabled by default (commented out). If enabled, task history is maintained in the lsw_em_task_history table. You can then query this table to get the history of your tasks. This table will contain a number of useful column including ERROR_MESSAGE column that would store an actual error message together with the stack trace of a failed EM task (UCA, timer, etc).
Here is how the table structure look like:
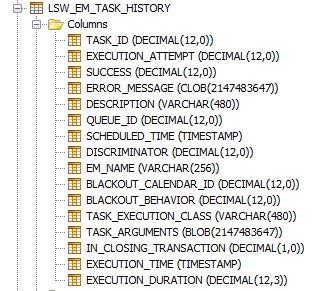
More information together with some queries you can use for performance metrics using history table can be found in a separate article here.
2) By default logging level for all servers is set to *=info. This may not be enough to see the root cause of the Event Manager problem. Default logging behavior can be changed through WebSphere Admin Console –
a) Login to the WebSphere Administrative Console
b) Navigate to Troubleshooting -> Logging and Tracing -> <*.AppServer> -> Change log detail levels -> Runtime tab
c) Change message and trace level to fine for the following two components
- WLE.* -> WLE.wle_eventmgr
- WLE.* -> WLE.wle_scheduler
Note that IBM BPM does not currently ship a way to display or cleanup this data but this table has no relation with any other BPM table and it's safe to truncate it overtime in case you decide to leave it enabled for a long period of time.
New in BPM 8.5.5 - EM thread pool
Starting BPM 8.5.5 EM no longer uses its own internal thread pool (corresponding EM xml settings - "min-thread-pool-size" and "max-thread-pool-size").
In 8.5.5 and onward EM is using Websphere work manager thread pool.
It's now controlled by the following settings in 80EventManager.xml:
<use-was-work-manager>true</use-was-work-manager> <was-work-manager>wm/BPMEventManagerWorkManager</was-work-manager>
So, as you can see it's still possible to disable (turn first setting to false) and use old internal thread pool instead of a WAS one. You may find configuration of new work manager thread pool in WAS admin console:
Resources -> Asynchronous beans -> Work managers -> bpm-em-workmanager
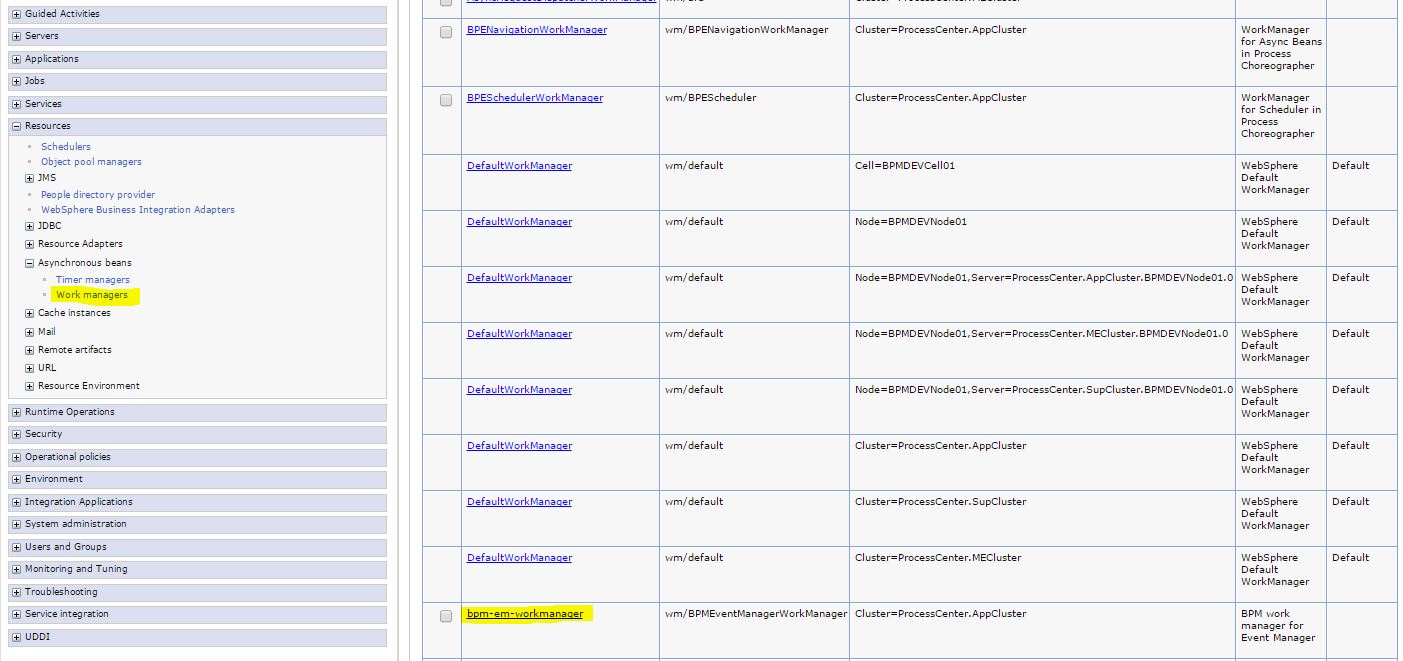
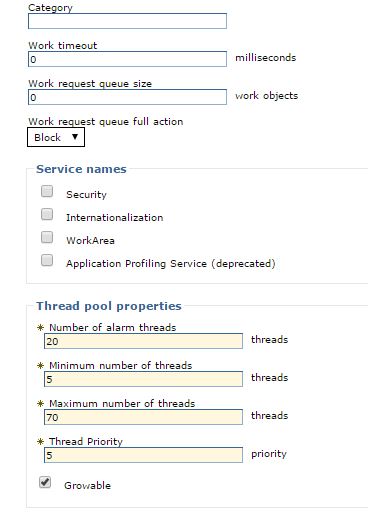
If you're going to change any of the thread pool settings please look into "Understanding general parameters of EM" section and corresponding references in that section. Basically you need to know that maximum number of threads and thread pool itself is not per queue; it is the total number of threads for that Event Manager instance in that particular Process Server Java virtual machine (JVM).
The rule of a thumb when changing max thread pool is - total available database connections in the application server connection pool should be at least 2x this number. The number of connections on the actual database server needs to be at least the sum of the max connection pool for all nodes in the cluster.
IMPORTANT NOTE (UPDATE AS OF 23rd JUNE 2018):
I have recently worked with a customer where Event Manager and as a result the whole IBM BPM were getting stuck consuming all the BPMDB datasource connections (max is set to 200 by default). I have found the following message always preceding the blocked/stucked EM threads -
[6/23/18 19:33:38:375 CEST] 00000159 ThreadPool I WSVR0651I: The WorkManager.bpm-em-workmanager
growable thread pool has grown to 2 times its initially-configured maximum of 70.As you can see in above screenshot there is a checkbox that is checked by default for the WAS EM workmanager called - "GROWABLE". This means that whenever there is not enough threads for the incoming traffic then WAS would automatically try to double the size of the thread pool and so, if you're getting into stuck/blocked situation on the Event Manager side then it would quickly cause the whole BPM to stop working (from an end user perspective) because it would consume all the BPM database datasource threads and users won't be able to login to Portal or perform any kind of activity. So, while Event Manager by itself should not cause the whole BPM to throttle in this specific case it would be the case because of the way this "growable" setting works. So, BP3 Labs suggestion is that you un-check this checkbox and instead fine-tune Event Manager as explained in this article and use a higher number of threads (if you know that need more than 70). Keep in mind the rule of thumb mentioned above (about db connections vs EM max thread pool number). You may also consider using the old method of Event Manager thread pool that was there for the last 10 years and we know that it worked fine. In old configuration (where WAS work manager is not used but internal thread pool is used) it's min/max values and no any "growable" option was available.
Other EM related tips
- The Event Manager is quick and efficient. Usually it is the tasks it is executing that slow it down, not the EM itself.
- If you want to throttle the Event Manager, don’t decrease the thread pool, instead decrease the queue capacity.
- A sync queue can get stuck since it will not advance until the task completes. To help make this less of a problem create multiple sync queues. You can manage sync queues in the IBM BPM Process admin console (Event Manager -> Synchronous queues).
- All the timestamps used by the EM scheduler - the heartbeat’s expirations and the task’s scheduled times - are interpreted relative to the database machine's system clock. Keeping system clocks in sync is always a good idea.
- In a clustered environment when you have more than two nodes in a cluster it often makes sense to disable/disconnect Event Manager on one of the nodes and to allow you to allocate this process server instance to user's web traffic or web services for instance. There is a parameter <enable>true</enable>
If set to true, the EventManager is turned on for this process server instance. If you set this to off, this process server EM will be in disconnected mode. Setting this to false also disables the bpd engine for this instance.
Comments
4 comments
Hello Sergei,
Nice article as usual.
I've got a question.
I add vertical clusterization on existing BPM AppTarget horizontal cluster (2 nodes x 1 server -> 2 nodes x 2 servers). Theoretically, two new EM for new servers must be created. But I see only two old EM in Process Admin console. Is it correct? Or, may be, it is some trouble/limitation/imperfection in the console?
Also I've an idea that there is some limitation linked with naming of EM instance. Usually it is named as hostname on standalone and using node name on cluster.
Hello Vladlen
Thank you!
Re vertical clustering - here is how it works starting BPM 8.x.:
in clustered env's it takes the app cluster server name and in turn app cluster server name consists of server name + node name.
That being said - there is a way how this can be overridden to a name you'd like by using <name> property in 80EventManager.xml (can be overridden in 100Custom.xml):
<!-- name of this scheduler instance, if we need to override the automatically looked-up name:
<name>BPMDEVNode01_DEVPC.AppCluster.BPMDEVNode01.0</name>
And yes, in your configuration you should have additional EM's to appear in EM Monitor page. Check your LSW_EM_INSTANCE table to see what's in there. You should have all EM's listed there.
Thanks
It works. Thank you.
Please sign in to leave a comment.